Order Statistics
Order Statistics
Let \(X_1,...,X_n\) indep. with unknown \(F\)
order \(X_1,...,X_n\) in increasing order \(X_{(1)}\leq ... \leq X_{(n)}\). Due to the independence assumption, the order statistics carry the same info about \(F\) as the unordered.
Also, the order statistics can be used to estimate the quantiles \(F^{-1}(\tau)\), such as median
Similarly, \(F^{-1}(\tau)\approx X_{k}, k \approx \tau n\)
Sample Extremums
with the independence assumption,
Sample Minimum
so that the pdf is \(g_1(x) = n[1-F(x)]^{n-1}f(x)\)
Sample Maximum
pdf is \(g_n(x) = nF(x)^{n-1}F(x)\)
Sample Distribution
Consider the distribution of \(X_{k}\)
First, define r.v. \(Z(x) = \sum^n\mathbb I(X_i\leq x) \sim Binomial(n,F(x))\) so that \(X_{(k)}\leq x = Z(x)\geq k\).
Then,
and
Central order statistics
Let \(k = k_n\approx \tau n, \tau \in (0,1)\), then \(X_{(k)}\) is called a central order statistic.
Intuitively, \(X_{(k)}\) is an estimator of the \(\tau\)-quantile \(F^{-1}(\tau)\), formally
Convergence in distribution of central order
Proof by using \(Unif(0,1)\) order statistics and then Delta method to generalize.
proof. Take \(U_1,...,U_n\) be independent \(Unif(0,1)\) r.v., and use the order statistics \(U_{(1)}\leq ... \leq U_{(n)}\).
Take \(E_1,E_2,...,E_{n+1}\) to be independent r.v. \(\sim Exponential(1)\). Let \(S=\sum_{i=1}^{n+1} E_i\)Note that
Then, we can approximate the distribution by sum of exponential r.v.
Assume \(\sqrt{n}(\frac{k_n}{n}-\tau)\rightarrow 0\), then
Note that
WTS \(\sqrt n \big(n^{-1}(E_1+...+E_{k_n}-\tau S)\big)\rightarrow^d N(0,\tau(1-\tau))\)
Let \(A\) be the summation
Using CLT,
Theorem If \(U\sim Unif(0,1)\) and \(F\) is continuous cdf with pdf \(f\) with \(f(x)>0\) for all \(x\) with \(0<F(x)<1\). Then \(X=F^{-1}(U)\sim F\). Therefore, for some cdf
are order statistics from \(F\).
Then,
Then we can use Delta Method, note that
So that
Quantile-quantile plots
Plot \(x_{(k)}\) versus \(F_0^{-1}(\tau_k)\) for \(k=1,...,n\).
According to the theory, if the data come from a distribution of this form then
where
Then, note that for fixed \(\tau_k, var(\tau_k)\rightarrow^{n\rightarrow \infty}0\)
Assess if data \(x_1,...,x_n\) are well-modeled by a cdf of the form \(F_0(\frac{x-\mu}{\sigma})\) for some \(F_0\).
Example: Normal QQ Plot
Given \(x_1,...,x_n\) then the steps are
- order \(x_1,...,x_n\) into \(x_{(1)}\leq ...\leq x_{(n)}\)
- let \(Z_{(1)}\leq ... \leq Z_{(n)}\) be the order statistics of a sample of size \(n\) from \(N(0,1)\) and define \(e_i = E(Z_{(i)})\) to be the expected values of the order statistics; \(e_i \approx \Phi^{-1}(\frac{i-0.375}{n+0.25})\)
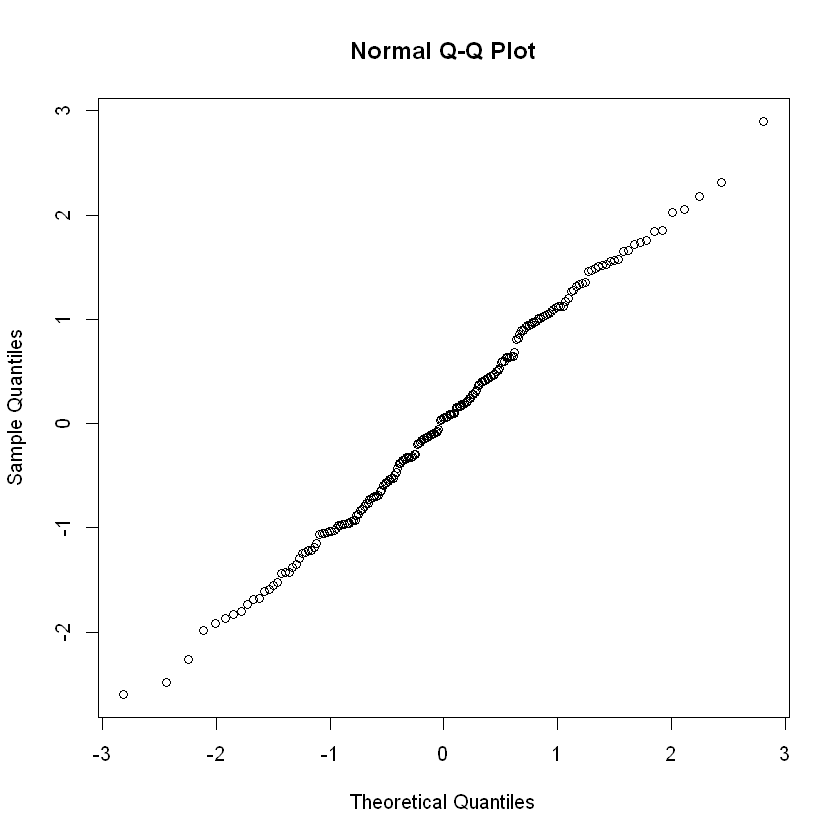
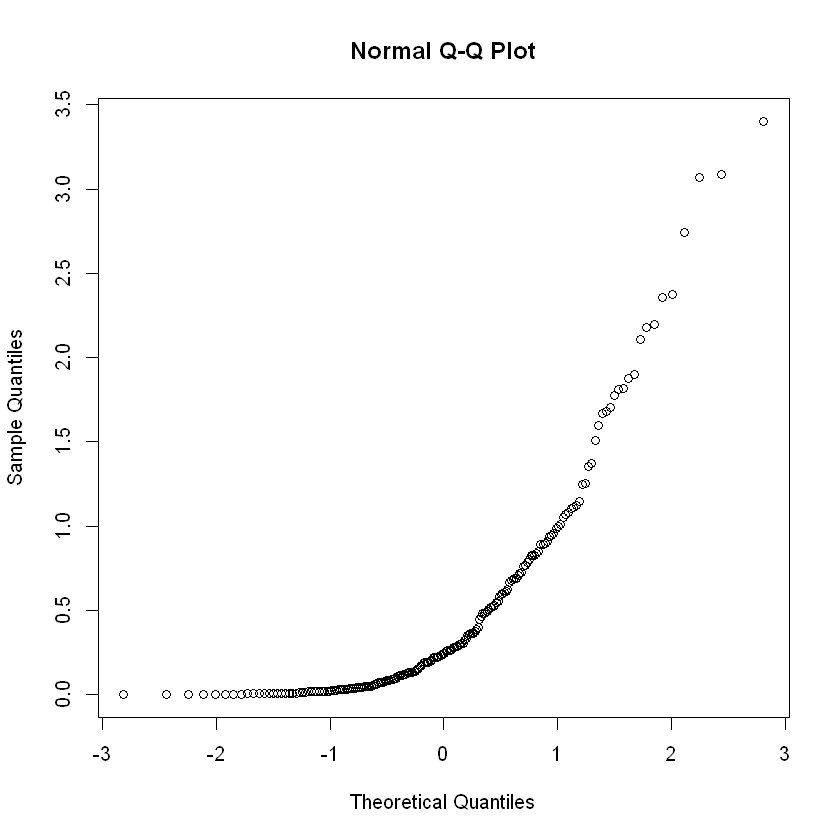
- Plot \(x_{(i)}\) vs. \(e_i\). If \(x_1,...,x_n\) do com from a normal distribution then the points should fall close to a straight line. If the plot shows a certain degree of curvature then notifies this may not be a normal model.
x1 <- rnorm(200) # generate random data from N(0,1)
qqnorm(x1)
x2 <- rgamma(200, shape=.5) # generate gamma with shape=0.5
qqnorm(x2)
Shapiro-Wilk Test
A formalized way of composing the normal QQ plot by the correlation between \(\{X_{(k)}\}\) and \(\{F_0^{-1}(\tau_k)\}\) where \(F_0 = N(0,1)\)
\(H_0:\) data come from \(N(\mu,\sigma)\) for some \(\mu,\sigma\)
statistic
where \(V[i,j] = cov(Z_{(i)}, Z_{(j)})\) and \(k_v\) is determined so that \(\sum a_i^2 = 1\).
For larger \(n\), then \(W\) is approximately
Shapiro-Wilk normality test
data: x1
W = 0.99369, p-value = 0.5554
Shapiro-Wilk normality test
data: x2
W = 0.6741, p-value < 2.2e-16