Neural Networks
Inspiration and Introduction
Unit simulates a model neuron by
The, by throwing together lots of processing unit, we can form a neural net.
Structure
A NN have 3 types of layers: input, hidden layer(s), output
Feed-forward neural network
A directed acyclic graph of connected neurons, starts from input layer, and ends with output layer.
Each layer is consisted of many units.
Recurrent neural networks allows cycles
Multilayer Perceptrons
A multiplayer network consisting of fully connected layers.
- Each hideen layer \(i\) connects \(N_{i-1}\) input units to \(N_i\) output units.
- Fully connected layer in the simplest case, all input units are connected to all output units.
- Note that the inputs and outputs for a layer are distinct from the inputs and outputs to the network.
Activation Functions
- identity \(y =z\)
- Rectified Linear Unit (ReLU) \(y = \max(0,z)\)
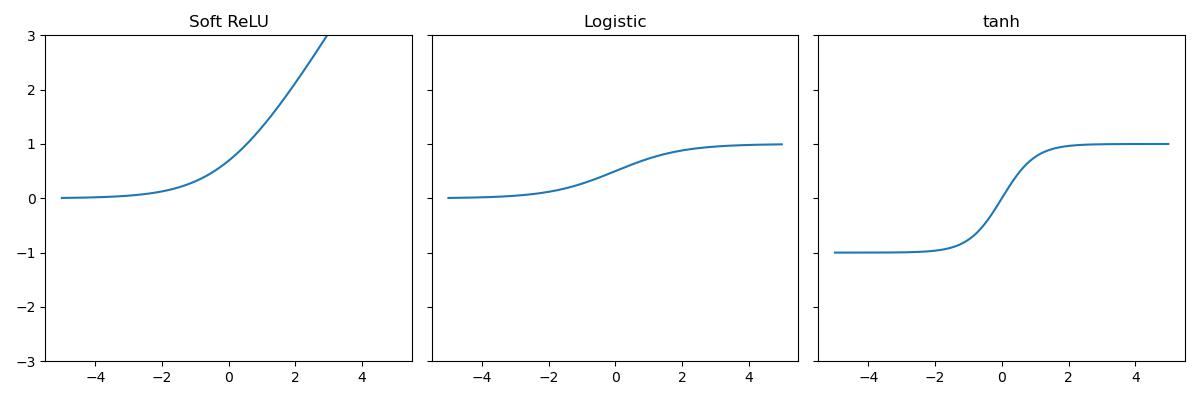
- Soft ReLU \(y = \log(1 + e^z)\)
- Hard Threshold \(y = \mathbb I(z > 0)\)
- Logistic \(y = (1+e^{-z})^{-1}\)
- Hyperbolic Tangent (tanh) \(y = \frac{e^z - e^{-z}}{e^z + e^{-z}}\)
Source code
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-5, 5, 0.01)
srelu = np.log(1+np.exp(x))
logit = (1 + np.exp(-x)) ** (-1)
a, b = np.exp(x), np.exp(-x)
tanh = (a - b) / (a + b)
fig, axs = plt.subplots(1, 3, figsize=(12, 4), sharey=True)
axs[0].plot(x, srelu); axs[0].set_title("Soft ReLU"); axs[0].set_ylim(-3, 3)
axs[1].plot(x, logit); axs[1].set_title("Logistic")
axs[2].plot(x, tanh); axs[2].set_title("tanh")
fig.tight_layout()
fig.savefig("../assets/neural_nets_activations.jpg")
Consider the layers,
Therefore, we can consider the network as a composition of functions
Therefore, neural nets provide modularity: we can implement each layer's computations as a black box.
For the last layer, if the task is regression, then the last activation function is identity function; if the task is binary classification, then is sigmoid function
Neural Network vs. Linear regression
Suppose a layer's activation was the identity, so is equivalent to an affine transformation of the input, then we call it a linear layer
Consider a sequence of linear layer, it is equivalent to a single linear layer, i.e. a linear regression
Universality
However, multilayer feed-forward neural nets with nonlinear activation function are universal function approximators, they can approximate any function arbitrarily well.
Problems
this theorem does not tell how large the network well be
we need to find appropriate weights
will eventually lead to overfit, since it will fit the training set perfectly
Back-propagation
Given a NN model (with number of layers, activation function for each layer). We then have the weight space being one coordinate for each weight/bias of the network, in all the layers. Then, we have to compute the gradient of the cost \(\partial \mathcal J / \partial \vec w\), a.k.a. \(\partial \mathcal L / \partial \vec w\)
Consider the NN
By chain rule
Univariate Example
flowchart LR
w --> z
x --> z
b --> z
z --> y
t --> L
y --> LDenote \(\bar y := \frac{\partial L}{\partial y}\), or the error signal. This emphasizes that the error signals are just values out program is computing, rather than a mathematical operation. Then,
Multivariate Perceptron example
flowchart LR
W1 --> z
x --> z
b1 --> z
z --> h
W2 --> y
h --> y
b2 --> y
t --> L
y --> LForward pass
Backward pass
Computational Cost
Forward: one add-multiply operation per weight
Backward: two add-multiply operations per weight \(\bar w, \bar h\)
Therefore, let the number of layers be \(L\), number of units for the \(l\)th layer be \(m_l\), then the computation time \(\in O(\sum_{l=1}^{L-1} m_im_{l+1})\), since each unit is fully connected with the next layer, and takes the weights as the number of units in its layer.
Overfitting Preventions
Reduce size of the weights
Adding regularizations onto each regression
Prevents unnecessary weights
Helps in improving generalization
Makes a smoother model in which the conditioning is good
Early Stopping
Starts with small weights and let it grow until the performance on the validation set starts getting worse
Because when the weights are very small, every hidden unit is in its linear range, so a net with a large layer of hidden units is linear, and it has no more capacity than a linear net in which the inputs are directly connected to the outputs.
While when the weights grow, the hidden units starts to use their non-linear ranges so the capacity grows.